Managed service providers (MSPs) deliver critical operational support for businesses around the world. As third-party providers of remote management, MSPs are typically contracted by small and medium-sized businesses (SMBs), government agencies and non-profit organizations to perform daily maintenance of information technology (IT) systems.
Similar to an MSP, managed security service providers (MSSPs) offer comparable organizations security management of their IT infrastructure, but are also enlisted to detect, prevent and respond to threats. An MSSP’s security expertise allows organizations that may not have the resources or talent to securely manage their systems and respond to an ever-evolving threat landscape.
Dark forces are increasing
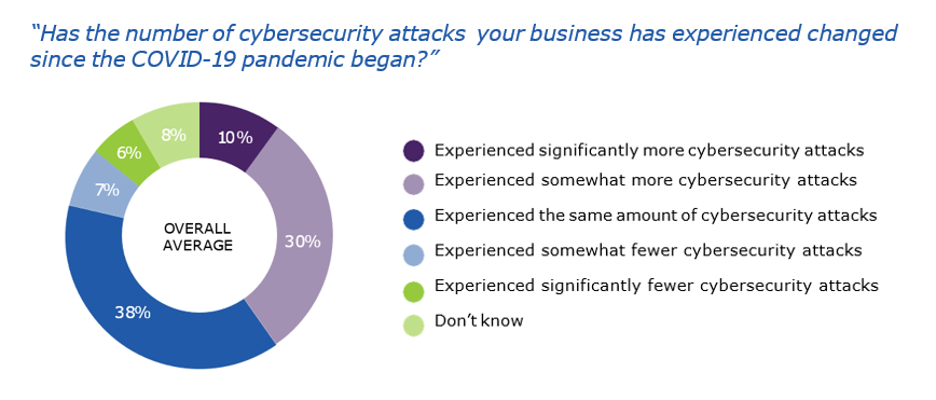
The rise of ransomware, malware and other malicious vectors has transformed the threat landscape. According to our Hidden Costs of Ransomware report, 46% of businesses said their clients were impacted by an attack. A single cyber attack could trigger as much as $80 billion in economic losses across numerous SMBs, not to mention the ongoing supply chain attacks that stand to cripple an MSP’s business. With all this in mind, many MSPs have considered evolving into an MSSP provider, but at what cost?
Competitive advantage and financial gain
Some of the driving forces fueling MSPs towards this security-infused business model are revenue generation and market share. With the global managed security services market expected to balloon to over 65 billion USD within the next five years, becoming an MSSP has many tangible benefits. MSPs have the chance to extend their current offerings, fueling additional benefits for customers and potential growth to their customer base at the SMB and mid-enterprise level.
How to get there
To be considered an MSSP, an MSP needs to secure high availability security operations centers (SOCs) to enable 24/7/365 always-on security for their customers’ IT devices, systems and infrastructure. SOCs are comprised of highly skilled professionals. These professionals are trained to detect and mitigate threats that could negatively impact a customer’s data centers, servers or endpoints.
MSPs can take three approaches towards establishing MSSP offerings:
- Build. MSPs considering this route will need to evaluate the cost and time associated with establishing its MSSP operations from the ground up. This requires a lot of money, time and resources to hire and train security personnel. These trained individuals must be capable of constant monitoring and regular calibration to ensure their customer’s systems are protected.
“Only a handful of MSPs in the industry have been able to transition themselves into MSSPs. The lack of bandwidth and resources needed to address compliance issues keep many MSPs at bay. The transition is incredibly resource-intensive,” says George Anderson, product marketing director at Carbonite + Webroot, OpenText companies.
- Buy. Opting to purchase an existing MSSP provider can enable an MSP to leverage current customers, processes and talent to service its existing customer base with the added benefit of providing data and network security. Purchasing an existing provider also allows MSSPs to extend their security offerings to a newly acquired set of customers. However, with little regulation, MSPs must do their due diligence to ensure they are purchasing a well-equipped provider.
- Partner. One of the most efficient options for an MSP to pursue is partnering with an existing well-established MSSP. This allows an MSP to capitalize on the existing partner’s security expertise without having to develop the initial financial resources or technical expertise to support the creation and maintenance of its SOCs.
“MSPs contemplating the move to an MSSP business model should consider the value of a partnering strategy with a well-known security provider. By partnering with an existing MSSP, an MSP will be able to securely protect its customer IT infrastructure and provide timely responses after hours to ensure efficient detection and response,” says Shane Cooper, manager, channel sales at Carbonite + Webroot.
Transition to MSSP: risk or reward?
Transitioning from MSP to MSSP brings with it a series of quantifiable benefits. However, MSPs need to consider the size and scalability of service offerings they can provide, not to mention the costs associated with initially building their services or acquiring them from another provider. Partnering with a seasoned security provider allows MSPs to maintain their customer base while tapping into the resources and talent of a skilled and experienced provider.
“Many customers may be unaware of the quality of their SOC provider. MSPs transitioning into an MSSP may lack the proper resources and talent to respond to threats. It pays to optimize your investment with a security stack that brings the robust service and security elements together,” says Bill Steen, director, marketing at Carbonite + Webroot.
Webroot offers an MDR solution powered by Blackpoint Cyber, a leading expert in the industry. Webroot’s turnkey MDR solution has been developed by world-class security experts and is designed to enable 24/7/365 threat hunting, monitoring and remediation.
Optimize and mature your security stack with a provider you can trust. Secure your stack with Webroot.
To learn more about why partnering with Webroot can help your business and support your customers, please visit https://www.webroot.com/ca/en/business/partners/msp-partner-program