






Discover 2022’s Nastiest Malware
For the past year, hackers have been following close behind businesses and families just waiting for the right time to strike. In other words, 2022 has been an eventful year in the threat landscape, with malware continuing to take center stage.
The 6 Nastiest Malware of 2022
Since the mainstreaming of ransomware payloads and the adoption of cryptocurrencies that facilitate untraceable payments, malicious actors have been innovating new methods and tactics to evade the latest defenses. 2022 was no different.
The ransomware double extortion tactic continues to wreak havoc, with ransomware attackers threating to both steal your data and also leak it if you don’t pay up. But this year also saw the onset of the triple extortion method – with this type of attack, hackers threaten to steal your data, leak it and then also execute DDoS attack if you don’t pay up. As a result, many organizations are shifting away from cyber insurance and adopting layered defenses in an effort to achieve cyber resilience.
Ransom payments continued to balloon – last year at this time the average was just below $150,000 but it now stands close to $225,000 (that’s increasing faster than the rate of inflation, for those counting at home!).
In bad news (as if we needed more), malicious actors seem to have settled on a favorite target: small and medium sized businesses. Large-scale attacks make headlines, but hackers have found that smaller environments make for easier targets.
But it’s not all bad news… after all, the first step in defeating your enemy is to learn their tactics. Our researchers have been hard at work uncovering the worst offenders to better build defenses against them. With that, here are the 6 Nastiest Malware of 2022.
Here are this year’s wicked winners
Emotet
- Persisting botnet with cryptomining payload and more
- Infects via emails, brute force, exploits and more
- Removes competing malware, ensuring they’re the only infection
Lockbit
- The year’s most successful ransomware group
- Introduced the triple extortion method – encryption + data leak + DDOS attack
- Accept payments in two untraceable cryptocurrencies Monero and Zcash as well as Bitcoin
Conti
- Longstanding ransomware group also known as Ryuk and a favorite payload of trickbot
- Shutdown attempts by US gov have made them rebrand into other operations such as Hive, BlackCat, BlackByte, and AvosLockerWill leak or auction off your data if you don’t pay the ransom
Qbot
- The oldest info stealing trojan still in operation
- Works to infect an entire environment to ‘case the joint’ before its final stage
- Creates ransomware Voltrons through partnerships with Conti, ProLock and Egregor
Valyria
- Malspam botnet that starts with email attachments containing malicious scripts
- Known for their complex payloads that can overwhelm defenses and evade detection
- Partners with Emotet to create a two-headed monster
Cobalt Strike / Brute Ratel
- White hat designed pen testing tool, that’s been corrupted and used for evil.
- Very powerful features like process injection, privilege escalation, and credential harvesting.
- The customizability and scalability are just too GOOD not to be abused by BAD actors
Protect yourself and your business
The key to staying safe is a layered approach to cybersecurity backed up by a cyber resilience strategy. Here are tips from our experts.
Strategies for business continuity
- Lock down Remote Desktop Protocols (RDP)
- Educate end users
- Install reputable cybersecurity software
- Set up a strong backup and disaster recovery plan
Strategies for individuals
- Develop a healthy dose of suspicion toward messages
- Protect devices with antivirus and data with a VPN
- Keep your antivirus software and other apps up to date
- Use a secure cloud backup with immutable copies
- Create strong, unique passwords (and don’t reuse them across accounts)
- If a download asks to enable macros, DON’T DO IT

Spending time with the Girl Scouts of Greater Chicago at Northwest Indiana’s CampCEO
Girl Scouts is proven to help girls thrive. A Girl Scout develops a strong sense of self, displays positive values, seeks challenges and learns from setbacks. I had the absolute honor of spending 3 days with the Girl Scouts in Chicago at the annual Camp CEO.
Camp CEO is a chance for the Girl Scouts to meet, talk to, and connect with the mentors who attend. More than that, though, it gave me a chance to learn from these girls. I was changed for the better after attending this camp. The girls shared their aspirations and fears. They were vulnerable with all of us, and grew tremendously even in the short time we spent together.
On day one, the girls were excited but hesitant. I remember that feeling at an event similar to this one, first day of school, even family and friend’s gatherings. It really had me reflecting on my career growth as well as my personal growth. I would not be where I am without key influential women in my life whether that be family, friends, or colleagues. I knew that I owed it to these girls to share about my successes as well as my failures and how I got there.
In order to make a meaningful connection, I wanted to first start by listening. Hearing firsthand the fears and goals they have was moving. While each girl had mentioned something different, there was a commonality there. Fears included things caused by lack of confidence, inability to problem-solve, and well-being of the community. While goals included things that require self-confidence, the ability to problem-solve, and the health of the community surrounding them.
Why this meant so much to me is each girl started the camp with more of a sense of doubt. This showed itself when they would hesitate to speak up, ask questions, or share an opinion. After we as mentors were able to lead by example and strike up conversations around us, share that we have had the same fears they feel now, and how we still experience them today and it’s okay to, we saw a difference.
What an incredible thing to see a change in a group of young women who will one day be our leaders, all within 3 days. By day 3, these girls were speaking before being asked to, making sure they voiced their opinions, and asked questions to learn how they can better themselves.
Spending time talking about and connecting around our stories really opened the door for these girls to understand it is okay to try when you’re scared, if anything, it is better to push yourself towards what you want. And along the way, you may look back and be shocked at where you landed. Having confidence in your values will assure you are always making the difference you are striving to make.
It was an honor to meet these girls and be able to give back by sharing my own teachings and experiences. While Camp CEO is meant to connect the Girl Scouts with resources they find in the mentors, I gained a resource and friend in each of these girls and cannot wait to celebrate them for years to come.

New Research Exposes Hidden Threats on Illegal Streaming Sites
Regional restrictions on NFL game broadcasts and rising membership fees on streaming sites like Netflix, Hulu, and Disney Plus are just some reasons why frustrated consumers turn to illegal streaming sites. Marketed as an alternative to legitimate streaming services, illegal streaming sites have become a portal to connect criminals directly to you (their target).
Unlike official streaming platforms that generate revenue from advertising or user subscriptions, illegal streaming sites must find alternative ways to make money—even if that means giving cybercriminals access to your information. Not surprising, these sites open a gateway for criminals to access bank accounts, commit fraud, and install malicious software. While computer antivirus is effective, sometimes malware still wins. Even the most tech-savvy viewer can fall victim.
With the NFL season kicking off and a host of new fall shows and movies rolling out, findings from the UK serve as a timely reminder to sports fans and movie enthusiasts around the globe to be cautious.

Threats are Real
New research from our threat team reveals the extent to which consumers are being exposed to fraud, dangerous scams, and explicit content on illegal sports streaming sites. Analysis of 50 popular “free-to-view” sites during several major sporting events uncovered that every single site contained malicious content, while over 40 percent of sites did not have the necessary security certificate.
To help you decide whether using illegal streaming websites are worth the risk, let’s dive into some of the threats our intelligence experts uncovered during their analysis.
- Banking trojans, a type of malware that is hidden under legitimate-looking software and designed to hack your bank accounts. For example, a banking trojan may be disguised as a mute button that, once clicked, automatically starts downloading a trojan onto your device. This type of malware acts extremely fast, and if your antivirus is not up to date, it may not recognize it.
- Phishing webpages, the most common type of malicious threat, are websites designed to look legitimate to fool you into providing your credentials. These scams offer the ability to view premium content as long as you log into your email hub or another important account that would be later used for identity fraud.
- Crypto scams, an increasingly popular malware that targets crypto apps on your phone. Crypto scams typically appear as pop-ups or redirects that show users fake stories of local politicians or celebrities to lure people into sophisticated financial ploys. These scams can seem very real and sometimes even imitate popular media publishing sites to sell the lie and get you to share your bank details. Another common crypto scam on these sites is malicious extensions that pretend to be a wallet for popular coins.
- Explicit content has surged on illegal streaming sites and it’s becoming more prevalent and more extreme each year. If you frequently lend your children your device beware, you be unknowingly exposing them explicit content.
How to stay safe
Cybercriminals have a deep bag of tricks, but there are some red flags you can look out for. Most of the illegal sites analyzed ran HTTP as opposed to HTTPS. While the difference of a single letter may not seem like much, “S” is crucial as it indicates encryption. An HTTPS site isn’t a guarantee that a website is entirely safe. However, its absence should always serve as a red flag not to use it.
Illegal streaming sites also are flooded with pop-ups and redirects to grab your attention and convince you to click–don’t! Links are pretty common and can be disguised as anything, making users highly vulnerable. And if an offer looks too good to be true, it usually is.
Avoid anything that wants to install an extension as part of the requirement to view content. This major red flag will typically lead to malware or phishing redirects.
Of course, the best way to say safe is to avoid risky free-to-view sites. Reliable antivirus that blocks malicious webpages will prevent you from opening and falling victim to these sites.

How to stop social engineering tactics
With social engineering now the #1 cause of cyberattacks, it’s imperative for you to learn how to stop social engineering attacks against your business.
Your first step in stopping them is to learn what they are and how they work. After that, you need to learn how combining security layers like Endpoint Protection and Email Security makes the best defense.
Read on and we’ll walk you through every step of the way.
What is social engineering and how does it work?
Social engineering tactics are based on a simple truth: it’s easier to hack a human than it is to hack a computer. That means social engineering attackers use deception and tricks to get their victims to willingly give up private information like logins, passwords and even bank info.
Phishing is the most common type of social engineering attack, and it works by disguising emails as someone or something you trust. We would never click on an email with the subject line “Click here to get hacked,” but we might click on an email titled “Your Amazon purchase refund – claim now.”
Why does combining security layers prevent social engineering?
Forrester unleashed their researchers to find the best defense against social engineering. They recommend layered defenses for preventing social engineering strategies like phishing.
Because social engineering attacks prey on the human element of cybersecurity, they’re very good at getting around single layers of protection. After all, locked doors only work when the bad guys don’t have a copy of the key.
But if your business is protected by both Email Security and Endpoint Protection, attackers can trick their way into an employee’s email password and still be foiled by Endpoint Protection. Or they might gain access to your network with an illicitly gained password, but Email Security stops their attack from spreading.
Stop social engineering
Now that you know how social engineering works and the best defense against this type of cyberattack, you’re well on your way to stopping social engineering.
The next step is making sure you have the right tools to stop cybercriminals in their tracks. Review your cybersecurity strategy to make sure you have multiple layers of protection like Email Security and Endpoint Protection.
Interested in achieving cyber resilience and gaining a partner to help stop cyberattacks? Explore Webroot Endpoint Protection and Webroot Email Security powered by Zix.

BrightCloud® Threat Report Mid-Year Update: Reinvention is the Name of the Game
When was the last time you secretly smiled when ransomware gangs had their bitcoin stolen, their malware servers shut down, or were forced to disband? We hang on to these infrequent victories because history tells us that most ransomware collectives don’t go away—they reinvent themselves under a new name, with new rules, new targets, and new weaponry. Indeed, some of the most destructive and costly ransomware groups are now in their third incarnation.
So, what does this mean for your business, your customers, your partners, and even your family as you vie to stay safe online and protect what matters most—data?
The OpenText Security Solutions threat intelligence team is sharing mid-year updates to our 2022 BrightCloud® Threat Report. With insight into the latest threats and trends, we are arming organizations with the knowledge they need to pivot and stay ahead of cyber criminals’ around-the-clock reinvention of malware, phishing, and brand impersonations.
MALWARE CONTINUES TO ITERATE, AND GROW

Malware Solution Option:
Windows 11 adoption remains very slow which highlights the importance of incorporating a layered security approach that includes DNS protection to help reduce infection rates.
Protective DNS services are essential components of today’s cyber resilience strategies because its protection not only offers added privacy, but also acts as a robust defense against malware. In fact, there are 31% fewer infections when endpoint and DNS protection are combined.

PHISHING PREYED ON A VOLATILE MARKET
Phishing activity was exceptionally high. Almost 20% of all first half of 2022’s attacks occurring in April, which was likely the result of tax season, the beginning of national gas hikes, and the baby food shortage.
Phishing continued to proliferate with 46% of all successful phishing attacks using HTTPS. Brands such as Google, Apple and PayPal were among the top ten so far this year for credential phishing, a process of obtaining login information from users.
Phishing Solution Option:
Consumers are still more likely to experience an infection than their business counterparts. Yet as more employees use personal phones and tablets for work, businesses must remain vigilant
Everyone benefits from ongoing security awareness training to reduce the likelihood of successful attacks that can wreak havoc on a business network and affect continuity.
The 2022 BrightCloud® Threat Report mid-year update emphasizes the need to increase cyber resilience using trustworthy and dependable security solutions like antivirus, DNS protection, and backup and recovery to help protect what matters most.
To learn more, go to: www.brightcloud.com

Top 5 Security Trends this Summer: RSA Conference & Black Hat 2022
The RSA Conference 2022 – one of the world’s premier IT security conferences – was held June 6th-9th in San Francisco. The first in-person event for RSA since the global pandemic had a slightly lower turnout than in years past (26,000 compared to 36,000 attendees). But attendees and presenters alike made up for it with their eagerness to explore emerging IT security trends that have developed over the past year – a venue like RSA Conference 2022 delivered on tenfold.
Following the remote work pivot we saw in 2020, IT security has had to evolve quickly to remain effective, flexible and resilient in today’s dynamic hybrid/remote work environments. This year’s RSA Conference and the upcoming Black Hat USA 2022 in August are providing vital venues for IT security pros and business leaders to address challenges in today’s rapidly evolving security landscape.
Here are some of the key trends which we observed at this year’s first marquee cybersecurity event post-pandemic:
1. Market landscape for XDR grows more crowded
RSAC was abuzz with numerous security providers – large vendors and small start-ups alike – promoting capabilities and options offering new flavors of EDR and MDR. Based on the customer and analyst interactions, it was evident that the definition of XDR is still evolving, and that customers are still trying to determine what is the best solution for their specific use case.
Most customers alluded to the cybersecurity skills shortage; one of the key market drivers remains a “managed” component tailored to organizations’ response capabilities. As the sophistication of malicious actors is growing rapidly, fundamentals such as initial compromise detection and lateral movement prevention still seem to define customers’ preferences.
2. Threat intelligence becomes key to addressing workforce gap
With new threats emerging daily, the industrywide shortage of skilled professionals is placing additional stress on security teams. Threat intelligence solutions using AI/ ML technologies can prevent false positives and reduce alert fatigue – helping cybersecurity professionals focus on strategic priorities instead of spending all their time reacting to security alerts and potential incidents.
We have seen this trend building over the years as increasing numbers of security appliance vendors have come to rely on our BrightCloud® Threat Intelligence for its accuracy, depth and contextual intelligence in order to stay a step ahead of a rapidly evolving threat landscape.
3. Cyber insurance becomes mainstream discussion
As cyberattacks have become more costly and more challenging to track, cyber insurance has gained prominence across the industry. Unfortunately, as cyber risks mount, insurers are raising prices for coverage, requiring customers to answer lengthy questionnaires and limiting who they provide cyber insurance coverage to.
The cyber insurance market is expected to reach around $20B by 2025. However, as MSPs and customers look to cyber insurance to manage their risk exposure, more emphasis is expected on the fine print of the coverage – in particular, on exclusions and limits around brand reputation and restoring normal operations.[NL1]
4. Business Email Compromise gains prominence
Although there is a mounting body of evidence that shows ransomware is and will continue to be a concern for businesses, there’s also an argument to be made for an eventual slowdown in ransomware attacks. As discussed at this year’s RSA conference, many preventative measures such as law enforcement crackdowns, tighter cryptocurrency regulations and ransomware-as-a-service (RaaS) operator shutdowns are putting pressure on ransomware perpetrators.
Phishing has now become the most popular avenue of attack for hackers because it’s relatively easy to trick people into clicking on malicious links. 96% of phishing attacks are sent via email – and 74% of US businesses have fallen victim to phishing attacks. This is what prompted the FBI to issue a warning about the $43B impact of Business Email Compromise (BEC) scams.
5. Cyber Resilience planning puts focus on recovery readiness
The growth in digital attack surfaces has added a new dimension to traditional data protection approaches in terms of compliance with emerging regulations. This theme was validated in the day-two keynote, where panelists reiterated the importance of data protection and governance in the context of privacy.
This year, ransomware events have increased by more than 10%, and the average cost of a data breach to organizations has risen to $4.2 million. Customers are increasingly taking steps to protect their data, with an emphasis on recovery and minimizing downtime. This growing focus on becoming cyber resilient is a wise course of action in a threat landscape in which malicious actors only need to get lucky once!

Can your business stop social engineering attacks?
Social engineering attacks like phishing, baiting and scareware have skyrocketed to take the top spot as the #1 cause of cybersecurity breaches.
So what makes social engineering so effective? When cybercriminals use social engineering tactics, they prey on our natural instinct to help one another. And as it turns out, those instincts are so strong that they can override our sixth sense about cybercrime.
But our urge to help people isn’t the only thing driving social engineering. Criminals are using new methods that target the vulnerabilities of hybrid workforces. These new tactics circumvent single layers of security and are so successful, cybercriminals are using them to target office workers.
Read on to learn how social engineering works, how to spot social engineering and how to stop social engineering.
How does social engineering work?
Social engineering is a type of cyberattack where criminals use deception to trick their victims into voluntarily giving up confidential information.
Here are some common social engineering tactics:
- Using social media to find personal information. Criminals are heading to social media sites liked LinkedIn to find their next victim – and they’re using any personal information they find to craft convincing phishing emails.
- Impersonation. Cybercriminals are taking advantage of the anonymity that comes with hybrid work arrangements to impersonate people. If you’ve never met anyone in your IT department it’s hard to know when someone is impersonating them.
- Targeting personal devices used for work. With the hybrid work boom here to stay, the lines between work and home life are blurring. Employees are now using work devices for personal matters and personal devices to connect to work. The problem? Personal devices often lack robust security.
How to spot social engineering
So how do you spot social engineering scams? Here are some of the tell-take signs you’re being targeted:
- Asking for log-in information. If you get a message asking you for log-in credentials – even if it’s from a trusted source – you’re probably the target of a social engineering attack. There’s no reason why someone else needs your login info, even if it’s your boss or your IT department.
- Urgently asking for money. Along the same lines, there’s almost never a reason why someone – even someone you know – would urgently need money.
- Asking to verify your information. This type of social engineering asks victims to verify their info to win a prize or a windfall. But even if the message is coming from a legitimate organization doesn’t mean it isn’t a scam with criminals spoofing an email or impersonating a business.
How to stop social engineering attacks
Now that you’ve learned the newest tactics and how to spot social engineering, all you need is to learn how to stop it.
Forrester recommends layered defenses for preventing social engineering strategies like phishing.* That’s because most social engineering attacks are so good at getting past single layers of cyber protection.
You and your business can stay safe from social engineering scams by combining Endpoint Protection and Email Security. You gain even more protection if you are able to add on Security Awareness Trainings and DNS Protection.
Each layer you add gives you a better chance of stopping social engineering tactics.
Want to learn more about social engineering and how to stop it?

Girl Scouts and OpenText empower future leaders of tomorrow with cyber resilience
The transition to a digital-first world enables us to connect, work and live in a realm where information is available at our fingertips. The children of today will be working in an environment of tomorrow that is shaped by hyperconnectivity. Operating in this environment means our present and future generations need to understand the importance of being aware of the benefits and risks of an interconnected world. Establishing a cyber resilient mindset is the first step towards navigating and thriving in this digital-first world. Cyber resilience is the continuous access to personal and business information, even in an era of unprecedented cyber threats.
This mindset is especially relevant for children, given their ongoing interaction with the online world through existing and emerging social media platforms, gaming sites and learning avenues. As the usage and reliance on technology to educate and entertain increases, so too does the risk of being exposed to threats. That’s why it’s so important for families to develop good cyber resilience habits while engaging online.
Cyber Resilience patch program
To help instill cyber awareness, the Girl Scouts of Greater Chicago and Northwest Indiana (GSGCNWI) and OpenText have collaborated to create a Cyber Resilience patch program to empower the Girl Scouts of today for leadership in a digital world tomorrow. This partnership will help raise awareness of the dangers that exist online and the importance of becoming cyber resilient.
The Cyber Resilience patch program provides Girl Scouts with the opportunity to engage in fun and educational hands-on activities that ignite awareness and create better online behaviors. The aim of the program is to educate Girl Scouts through lessons that focus on simulations of existing and emerging threats, how to safely preserve important files and memories and what to look out for when browsing online.
General tips for children and parents
Staying resilient against ongoing threats means adopting important ways of protecting our personal information.
- Password integrity: Develop a password that is difficult to predict. Use a password generator, enable two-factor authentication (2FA) as much as possible and don’t reuse passwords from multiple logins.
- Back up personal data: Your photos and videos are precious. If you don’t secure them, you may lose them. Backing up your files means having a second copy available if something happens to your laptop, tablet or phone.
- Enable a Virtual Private Network (VPN): Protect your connection and location from malicious hackers, targeted ads and others who try to spy and track your every move online.
- Invest in security awareness training: Engaging in real-world simulations will help increase your cyber know-how.
Building a better future through cyber resilience
Creating leaders of tomorrow who are empowered and cyber aware begins with establishing cyber resilience today. Families and children should be working towards a better, more agile understanding of the risks to our personal information. Protecting the photos, videos and files that matter to us is important. Keeping our personal identities safe is vital.
OpenText remains committed to not only helping organizations find value in their data but also bolstering female leadership and diversity. The partnership between OpenText and GSGCNWI will help instill the importance of developing cyber safe behaviors now and for the future.

Cyber threats in gaming—and 3 tips for staying safe
The popularity of online gaming surged during the COVID-19 pandemic—and so did cyberattacks against gamers. If you’re the parent of a gamer, or if you’re a gamer yourself, it’s important to learn about the risks.
Why are cyber threats to gamers on the rise?
It might seem strange that cybercriminals are targeting gamers. But there are some good reasons for this trend:
- The global gaming market is booming—and is expected to reach $219 billion by 2024. Whenever that much money is floating around, bad actors will look for a way to take advantage.
- The average cost of games is rising, making “cracked” or pirated games more of a temptation. Unfortunately, hackers realize this and use the lure of free games to infect people with malware.
- A huge economy has developed within the gaming community: People buy and sell in-game objects, character modifications, and even accounts. This provides an incentive for hackers to steal and resell other people’s digital property.
- Many gamers are unaware of the cybersecurity risks that they face. In addition, many younger people are involved in gaming. This means lots of easy targets for cybercriminals.
Top cyber threats in gaming
There are numerous cyber threats to gamers. But you’ll get the most benefit out of focusing on the following three:
- Malware. Malware threats to gamers are spread through malicious websites, exploited system vulnerabilities, or Trojanized copies of pirated games.
- Account takeovers. Bad actors are always on the lookout for easy-to-breach gaming accounts. Once stolen, they can resell an account or its contents to interested buyers.
- Phishing and social engineering. Gaming is now an online social activity. This gives scammers lots of opportunities to approach unwary gamers and try to trick them into downloading malware, giving up personal details, or handing over login credentials.
Cybersecurity tips for gamers
It’s scary to think that cybercriminals are attacking gamers with greater frequency. But the good news is that taking a few basic precautions can keep you safe:
- Protect your accounts. If you have a gaming account with Steam, Epic, or another large gaming platform, take steps to keep it safe just as you would a banking or social media account. Use a strong, unique password for every account that you have. If possible, enable two-factor authentication (2FA) on your gaming accounts as well.
- Avoid pirated games. We get it, games are expensive and times are tough. But hackers love to sneak malware into those “free” copies of popular games. As such, downloading a pirated game simply isn’t worth the risk.
- Watch for phishing and social engineering. As the saying goes, if you’re online, you’re a target. The best way to stay safe is to be aware of the threat—and learn how to spot phishing and social engineering attacks when you encounter them.
Following these basic cybersecurity tips will help to make your online gaming experience more secure.
For even more protection, explore Webroot’s SecureAnywhere Internet Security Plus antivirus solution. It will keep your system safe from all types of malware threats—and includes access to LastPass®, a reliable and easy-to-use password management tool.

Webroot managed detection and response (MDR) purpose-built for MSPs
The cyber threat landscape keeps evolving at lightning-speed. According to the latest 2022 BrightCloud® Threat Report, small to medium-sized businesses (SMBs) are particularly vulnerable to becoming a victim of a ransomware attack. Cybercriminals also are becoming more selective of the organizations they target. Without human security experts and solutions at their disposable, these businesses remain susceptible to attacks.
As an MSP, there’s never been a better time to partner with a leading MDR provider to help protect your SMBs against cyberattacks. Minimize business operational disruption, maximize ongoing business continuity and bolster customer confidence with Webroot MDR.
What is MDR?
MDR is an approach to proactively manage threats and malicious activity that empowers organizations to become more cyber resilient. MDR services offer threat detection and response capabilities by augmenting cybersecurity tools with human security intelligence. Leveraging this human security expertise, MDR integrates, synthesizes and contextualizes security and other event information to hunt for, understand and respond to security incidents. This allows MSPs to offer the best combination of human expertise and a robust technology stack to help small businesses defend against future attacks.
Since MDR helps to close the gap between detection and response to threats, SMBs greatly benefit from this solution. As an MSP, you are the trusted advisor to provide your SMBs with an MDR solution to help boost their overall security stack and embrace cyber resilience.
Why should MSPs choose Webroot MDR?
SMBs are often attractive targets for bad actors looking to steal valuable data, extort money from their victims and more. We know there are many MDR solution providers on the market. However, Webroot MDR powered by Blackpoint provides a unique offering in the marketplace.
Here’s what separates Webroot MDR powered by Blackpoint from the competition:
- The fastest time in the industry from threat detection to response in 9 minutes
- A patented SNAP-Defense platform recognized by Gartner
- Best-in-class AI augmented by NSA security experts
- A competitively priced offering with unique threat detection and response capabilities
As an MSP, making the choice to purchase Blackpoint MDR through Webroot gives you:
- Seamless integration between Webroot and Blackpoint agents for quicker event investigation
- Accurate and timely insights from the BrightCloud® Threat Intelligence platform
- One-stop shop for cyber resilience that includes MDR
- Potential to obtain and lower cyber insurance costs
Ransomware, malware and phishing threats keep evolving. Your SMB customers likely don’t have the necessary security staff and tools to protect and respond to these threats. Help your customers avoid becoming a victim of data theft and extortion with industry-leading, reliable threat detection and response from Webroot. Our MDR solution can help reduce the impact of successful attacks.
Ready to discover what Webroot MDR can do for you and customers? Tune into our latest webinar.

Improved functionality and new features to help enhance the user experience
Webroot Console 6.5 is here
To help get us closer to retiring the Endpoint Protection Console, we’ve introduced three new functionality features with Webroot Console 6.5.
Friendly name support
To improve overall user functionality within the existing Endpoint Console, we have introduced a naming convention feature that allows users to assign a device a ‘Friendly Name’ that will replace the original Hostname associated with a device. All devices renamed within the Endpoint Console will see this naming convention reflected in the Management Console, allowing users to manage devices without having to navigate down to the Endpoint Console.

Persistent states
To further improve the user experience, the sites and entities pages has been improved with the introduction of persistent states. This introduction allows filters and searches to persist across a user’s session. Admins can seamlessly navigate away from a page and return to the view they were previously working with. This type of functionality will be introduced across other areas of the console in future releases.
Site only Admin view
This release brings forth a new look and feel for Site Only Admins to help align with the rest of the Webroot Management Console. This view represents the beginning for Site Only Admins. Admins will still have access to the Endpoint Protection Console during the uplift process in upcoming releases.
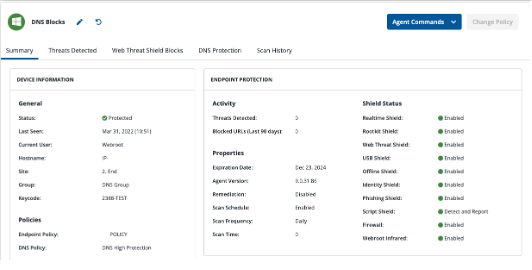
The release of Webroot’s latest console provides users with a simplified and centralized management system, intuitive user experience and enhanced visibility.
Visit our portal to get the latest Webroot updates in real-time.
Browse the status of product updates and enable delivery notifications.

World Password Day and the importance of password integrity
Passwords have become a common way to access and manage our digital lives. Think of all the accounts you have with different providers. Having a password allows you to securely access your information, pay bills or connect with friends and family on various platforms. However, having a password alone is not enough. Your password for each of your accounts needs to be difficult to guess and unpredictable. Your passwords also need to be managed and protected. With World Password Day around the corner, it’s important to take a moment and reflect on the importance of strengthening our digital hygiene beginning with our passwords.
When it comes generating a password, most of us rely on things that we can remember. A birth date, a pet’s name or our favorite sports team. While these options make it easier for us to recall our passwords, it also makes it far simpler for a cybercriminal to uncover them too. With all of the information we are freely sharing online through our social media platforms, a cybercriminal can easily spend a very small amount of time researching our habits, connections and other elements of our lives to guess potential passwords and gain access to our information. That’s why maintaining password integrity helps protect our online lives and reduces the risk of becoming a victim of identity theft or data loss.
What is password integrity?
Think of the foundation of a building. To prevent the building from collapsing in the future causing serious harm, it needs to be built with certain principles in mind. Password integrity involves the same concept. Passwords are the foundation of our digital lives. If they aren’t secure or properly managed, we run the risk of falling victim to cybercriminals who are eager to access our personal data.
Predicable passwords are problematic for several reasons. If your passwords follow the standard guidelines offered by most sites that require a single capital letter, at least 6 charters, numbers and one special character, hackers can easily make a series of attempts to try and gain access.
Without proper password integrity, personal information and business data may be at risk. The impacts for businesses and consumers are enormous. The average cost of a data breach in 2021 rose to over 4 million dollars, increasing 10% from 2020. For some small to medium-sized (SMBs) businesses, this means incurring a financial hit that could mean closing up shop. For consumers, dealing with identity theft can involve a world of headache. From freezing credit cards and assets to contacting all of the companies you regularly interact with, recovering from identity theft can be difficult and time consuming.
How to develop password integrity
The best way to prevent unauthorized access to your accounts is to protect and manage them. While avoiding duplication of passwords for multiple accounts and enabling two-way authentication can help, using a password manager is another way to help manage all of your account passwords seamlessly.
Included in Webroot’s SecureAnywhere Internet Security Plus antivirus solution is access to LastPass®, a reliable and secure password management tool. LastPass is the most trusted name in secure password management. It encrypts all username, password and credit card information to help keep you safe online. LastPass gives you access to a password vault to store and access all of your passwords from any device.
Securing your digital life means protecting and managing your information. Having a reliable password management tool can help you effortlessly manage all of your passwords. As World Password Day approaches, take a step back and assess your digital hygiene beginning with your passwords. As cybercriminals develop more sophisticated ways to steal our information or identity, maintaining our own password integrity becomes key.
Discover Webroot’s antivirus solutions and learn more about LastPass.