






AI in education: Balancing innovation with security
Artificial intelligence (AI) and chatbots like ChatGPT are transforming the way educators and students approach education. It’s not just college students leveraging AI to get ahead; high school and even grade school students are using AI resources for their projects and homework. Students can write essays, get math tutoring help, and even create study plans using these advanced tools.
While AI offers numerous educational benefits, it also presents challenges like cheating and plagiarism. Understandably, the use of AI has raised questions for many educators who must balance its educational value while also ensuring students do not misuse the technology. They must now address topics about academic integrity and the authenticity of student work in the context of AI’s influence.
Interestingly, 63% of teachers are incorporating ChatGPT into their instruction methods; yet, when it comes to schoolwork, 62% of teachers prohibit students from using AI. Educators are now tasked with finding ways to ensure students use these tools ethically. Implementing plagiarism checks and fostering an environment that values original thought are crucial steps in addressing this issue. Likewise, by promoting a culture of authenticity and integrity, schools can ensure that AI serves as a valuable educational tool rather than a shortcut for students.
Data security and privacy concerns
Then, there’s the security considerations with AI use in school. With the increased reliance on AI in education, safeguarding students’ data has become a critical issue. It’s essential to protect sensitive information, such as academic records and personal data, from theft, breaches, and misuse. This includes addressing emerging threats like malware and ransomware to ensure comprehensive data security. Likewise, having dark web and identity theft monitoring in place is crucial to preemptively address potential risks to student data security.
As educators and parents explore the benefits of AI tools for enhancing learning experiences, having robust security in place is essential. Comprehensive protection tools like Webroot deliver all-in-one device, privacy & identity protection to safeguard against cybercriminals and identity theft. These tools provide features such as malware protection, private browsing with VPN, and identity theft protection, which safeguard against cyber threats, protect online privacy, and monitor for unauthorized use of personal information.
By integrating robust security solutions, educators and parents can effectively mitigate risks associated with AI use while promoting a safe and trusted learning environment. This holistic approach strengthens data security measures and supports the responsible integration of AI in education.
The future of AI in education
As AI continues to evolve, its role in education will likely expand. The key to harnessing its potential lies in striking a balance between leveraging its benefits and mitigating its risks. By promoting ethical use, enhancing data security, and fostering a culture of originality, we can ensure that AI becomes a valuable asset in the educational landscape.
Ultimately, AI’s future in education will depend on collaborative efforts between educators, policymakers, technology developers, and communities. By fostering innovation and embracing AI responsibly, we can prepare students for a future where technological advancements and human creativity go hand in hand.

7 tips on keeping your data private when using AI
In recognition of its profound impact, July 16 is celebrated as Artificial Intelligence (AI) Appreciation Day. AI is one of the defining technologies of our era, and its adoption is skyrocketing. People are using AI tools like OpenAI’s ChatGPT and Microsoft Copilot for a wide range of personal applications. Indeed, AI is integrated into various aspects of our daily lives — from AI-powered apps that assist with language translation and personal finance management to tools that help with creative writing and music composition.
However, with the rapid growth of AI comes the pressing need to maintain privacy in our tech-driven world. As these intelligent systems become more capable and ubiquitous, they also collect vast amounts of data. Staying informed about the privacy practices of the AI tools you use and taking proactive steps to safeguard your information is crucial in navigating this new digital landscape.
Here are some tips to help you keep your data private in our AI-enabled era:
- Understand the technology
Imagine stepping into a futuristic world where robots and computers are your helpful companions. That’s our world today with AI! But as with any new tech, it’s crucial to know how it works. AI is evolving fast, so take some time to understand the basics. Knowing how AI algorithms function and the specific types of data they use is key to understanding how these systems make decisions. - Know the vendor’s privacy practices
Think of using an AI tool like choosing a new roommate. You wouldn’t want to live with someone who’s careless with your belongings, right? The same goes for your data privacy. Before you start using any AI tool, look into how the company handles your information. Are they safeguarding it, or selling it off to the highest bidder? A little research can help you find AI tools that respect your privacy. - Avoid inputting private data
Avoid sharing sensitive information like your address and phone number when interacting with AI tools. While it’s important to be cautious, remember that certain types of private data, such as preferences or non-sensitive information, can be safely shared with AI. Just as you wouldn’t divulge all your secrets to a new acquaintance, exercise discretion in what you share to ensure your privacy remains protected. - Use strong passwords
Think of your passwords as the locks on your doors. Weak locks are easy to pick, while strong ones keep intruders out. Create strong, unique passwords for your accounts, and use a reputable password manager like Webroot to keep track of them. This way, you won’t have to remember each one, and you can rest easy knowing your accounts are secure. - Keep software up-to-date
Imagine driving a car with outdated brakes — scary, right? Using outdated software is just as risky. Keep your AI-powered devices and services up-to-date. Software updates often include security patches and bug fixes that keep your data safe and your devices running smoothly. - Protect your devices
Your devices are like digital treasure chests, full of valuable information. Unfortunately, they’re also targets for cyber-attacks. AI-powered cyber threats are common and can wreak havoc on your systems. So strong antivirus protection is essential. Invest in a powerful solution like Webroot to keep the bad guys out and your devices safe. - Use two-factor authentication
Think of two-factor authentication (2FA) as a double lock on your front door. It adds an extra layer of security by requiring a second form of verification, like a text message or an app notification, along with your password. Enabling 2FA on your accounts makes it much harder for someone to break in, even if they know your password.
By following these tips, you can enjoy the wonders of AI without sacrificing your privacy. Stay informed, stay cautious, and stay protected! The future is bright with AI — just make sure you’re navigating it safely.

What to do if you’re using Kaspersky security software that is now banned in the U.S.
If you’re using cyber security software from Kaspersky Lab, Inc, you will need to find an alternative solution soon. On June 20, 2024, the U.S. Department of Commerce banned software from the Russian-owned company, saying it posed an unacceptable risk to national security.
Citing the Russian government’s offensive cyber capabilities and its capacity to influence Kaspersky’s operations, Commerce Department regulators are strongly encouraging individuals and businesses that use Kaspersky products and services to transition to new vendors to limit potential exposure of personal or sensitive data.
While customers won’t face legal penalties for continuing to use the software, federal regulators caution that users will assume any risks associated with a breach.
The only good news is that current users of Kaspersky software are being given several months to transition to alternative cyber security products — until 12:00 AM EDT on September 29, 2024.
Factors to consider when evaluating antivirus software
After events like this, you may wonder how much it matters where your cyber security solutions are developed and headquartered. Effective cybersecurity solutions can come from any corner of the globe, and transparency and openness to independent review are far more important factors than national origin.
So how do you go about evaluating and selecting antivirus software?
Once you’ve looked around and realized that a free solution won’t provide the protection you need, you’ll want to consider protecting yourself with software from one of the well-established industry leaders in this space. Here’s what a best-in-class provider like Webroot® has to offer:
- Regular definition updates – In the age of polymorphic malware and zero-day phishing attacks, any software with regular, cloud-initiated definition updates is out of date by the time it’s installed on your computer.
- Refined malware detection – The threat landscape in the field of cybersecurity is always evolving. You need a multi-layered approach to malware protection.
- Designated threat research team – While AI is increasingly important in the field of internet security, there’s still no substitute for a team of trained professionals to sift through the data and identify the latest cyber threats.
- Customer service – You’ll want to rely on team of threat researchers with award-winning support available 24/7.
- Reliable and reputable – The number of cyber security companies and products has exploded in recent years. But you should give greater weight to one of the well-established market leaders in this space. Webroot, for example, was founded in 1997 in Boulder, CO. The brand is now part of OpenText, a global leader in Enterprise Information Management.
Resources to help you choose the right antivirus
Personal or business: Business requirements (think networks, fleets of computers, and downtime risks) are different than those of an individual trying to protect their laptop and mobile device. Webroot has products tailored to both business and personal use.
Need help choosing? Evaluating security solutions and matching them to your needs can be daunting. Consider using Webroot’s self-guided tools to help you pick a personal or business product.
Try before you buy: You can kick the tires on Webroot’s products for free. Try the personal free trials here. Or try the business free trials here.

Internet Safety Month: Keep your online experience safe and secure
What is Internet Safety Month?
Each June, the online safety community observes Internet Safety Month as a time to reflect on our digital habits and ensure we’re taking the best precautions to stay safe online. It serves as a reminder for everyone—parents, teachers, and kids alike—to be mindful of our online activities and to take steps to protect ourselves.
Why is it important?
As summer approaches and we all pursue a bit more leisure time—that typically includes more screen time—it’s important to understand the risks and safeguard our digital well-being. While the Internet offers us countless opportunities, it also comes with risks that we must be aware of:
This makes Internet Safety Month the perfect time to review our digital habits and ensure that we are doing everything we can to stay safe.
7 tips to keep your online experience secure
Malware is malicious software designed to harm your computer or steal your personal information. It can infect your device through malicious downloads, phishing emails, or compromised websites, leading to potential loss of access to your computer, data, photos, and other valuable files.
How to protect it
Install reputable antivirus software like Webroot on all your devices and keep it updated. Regularly scan your devices for malware and avoid clicking on suspicious links or downloading unknown files.
2. Be skeptical of offers that appear too good to be true
If an offer seems too good to be true, it probably is. Scammers often use enticing offers or promotions to lure victims into sharing personal information or clicking on malicious links. These can lead to financial loss, identity theft, or installation of malware.
How to protect it
If an offer seems too good to be true, it probably is. Research the company or website before pursuing an offer or providing any personal information.
3. Monitor your identity for fraud activity
Identity theft happens when someone swipes your personal information to commit fraud or other crimes. This can wreak havoc on your finances, tank your credit score, and bring about a host of other serious consequences.
How to protect it
Consider using an identity protection service like Webroot Premium that monitors your personal information for signs of unauthorized use. Review your bank and credit card statements regularly for any unauthorized transactions.
4. Ensure your online privacy with a VPN
Without proper protection, your sensitive information—like passwords and credit card details—can be easily intercepted by cybercriminals while browsing. Surfing the web and using public Wi-Fi networks often lack security, giving hackers a prime opportunity to snatch your data.
How to protect it
Use a Virtual Private Network (VPN) when connecting to the internet. A VPN encrypts your internet traffic, making it unreadable to hackers. Choose a reputable VPN service and enable it whenever you connect to the internet.
5. Avoid clicking on links from unknown sources
Clicking on links in emails, text messages, or social media from unknown or suspicious sources can expose you to phishing attacks or malware. These seemingly harmless clicks can quickly compromise your security and personal information.
How to protect it
Verify the sender’s identity before clicking on any links. Hover over links to see the actual URL before clicking. If you’re unsure about a link, type the company’s name directly into your browser instead.
6. Avoid malicious websites
Malicious websites are crafted to deceive you into downloading malware or revealing sensitive information. Visiting these sites can expose your device to viruses, phishing attempts, and other online threats, putting your security at risk.
How to protect it
Install a web threat protection tool or browser extension that can block access to malicious websites. Products like Webroot Internet Security Plus and Webroot AntiVirus make it easy to avoid threatening websites with secure web browsing on your desktop, laptop, tablet, or mobile phone.
7. Keep your passwords safe
Weak or reused passwords can easily be guessed or cracked by attackers, compromising your online accounts. But keeping track of all your unique passwords can be difficult if you don’t have them stored securely in a password manager. If one account is compromised, attackers can gain access to your other accounts, potentially leading to identity theft or financial loss.
How to protect your passwords
Use a password manager to create and store strong, unique passwords for each of your online accounts. A password manager encrypts your passwords and helps you automatically fill them in on websites, reducing the risk of phishing attacks and password theft.
Take action now
As we celebrate Internet Safety Month, take a moment to review your current online habits and security measures. Are you doing everything you can to protect yourself and your family? If not, now is the perfect time to make some changes. By following these tips, you can enjoy a safer and more secure online experience.
Remember, Internet Safety Month is not just about protecting yourself—it’s also about spreading awareness and educating others.
Sources:
[1] Forbes. The Ultimate Internet Safety Guide for Kids.
[2] Forbes. The Ultimate Internet Safety Guide for Kids.

Graduation to adulting: Navigating identity protection and beyond!
Congratulations, graduates! As you gear up for life after high school or college, you’re stepping into a world of exciting firsts—new jobs, new homes, and new adventures. There’s one first you might not have considered: your first identity protection plan.
Why is identity protection important? Let’s dive in.
Why protecting your identity matters
Imagine this: you’re building your credit score, applying for a credit card, or renting your first apartment. These milestones are crucial, but they also make you a prime target for identity theft and fraud. Your credit score is your financial fingerprint—it impacts job opportunities, apartment rentals, and even car loans. Protecting your identity from fraud is key to a smooth transition into adulthood.
Plus, as you start crafting resumes and portfolios for your dream job, your devices become treasure troves of personal information. Losing them to cyber threats can compromise your future. This is where identity and virus protection step in.
Understanding the risks
Identity theft and fraud pose significant risks, especially for new graduates entering the world of financial independence. As you start using credit cards or taking out loans, you become a prime target for cybercriminals looking to exploit your personal information. If your identity is stolen, it can wreak havoc on your credit history and financial well-being.
But it’s not just about identity theft. Your personal devices—laptops, smartphones, and tablets—hold a wealth of sensitive information that cybercriminals target through malware, ransomware, and other cyber threats. From important resumes and portfolios to personal documents, your digital footprint needs robust protection.
Safeguarding against identity theft and cyber threats
To protect yourself against these digital risks, consider adopting the following technology approaches:
Protecting your identity and personal information is essential as you embark on your journey into adulthood and financial independence. By incorporating these technology solutions into your digital habits, you can significantly reduce the risk of identity theft, fraud, and cyberattacks.
Choosing the right protection
Now, let’s talk about finding the right protection for you. Do you have multiple devices that need safeguarding? Are you protecting just yourself, or your family too? These are the questions that will guide your choice.
Enter Webroot. Webroot can help you navigate the complex world of identity, privacy, and virus protection. With a range of options, you can select the level of security that fits your lifestyle and needs. Worried about credit fraud? Interested in keeping your devices secure? Webroot has you covered.
Ready to make your first smart adulting decision? Explore Webroot’s protection plans and secure your future today.

Key Insights from the OpenText 2024 Threat Perspective
As we navigate through 2024, the cyber threat landscape continues to evolve, bringing new challenges for both businesses and individual consumers. The latest OpenText Threat Report provides insight into these changes, offering vital insights that help us prepare and protect ourselves against emerging threats. Here’s what you need to know:
The resilience of ransomware
Ransomware remains a formidable adversary, with groups like LockBit demonstrating an uncanny ability to bounce back even after significant law enforcement actions. Despite a recent crackdown that saw authorities dismantle its infrastructure, LockBit swiftly resumed operations, even taunting law enforcement agencies in the process. This adaptability highlights how resourceful ransomware groups have become, enabling them to evade detection and persistently challenge defenders.
For businesses, this means implementing a comprehensive incident response plan that includes secure, immutable backups and regular testing to ensure rapid recovery in the event of an attack. Consumers should also take measures like frequently backing up their data to an external drive or cloud solution. This resilience requires ongoing vigilance and robust security measures for everyone involved.
Malware infections on the rise
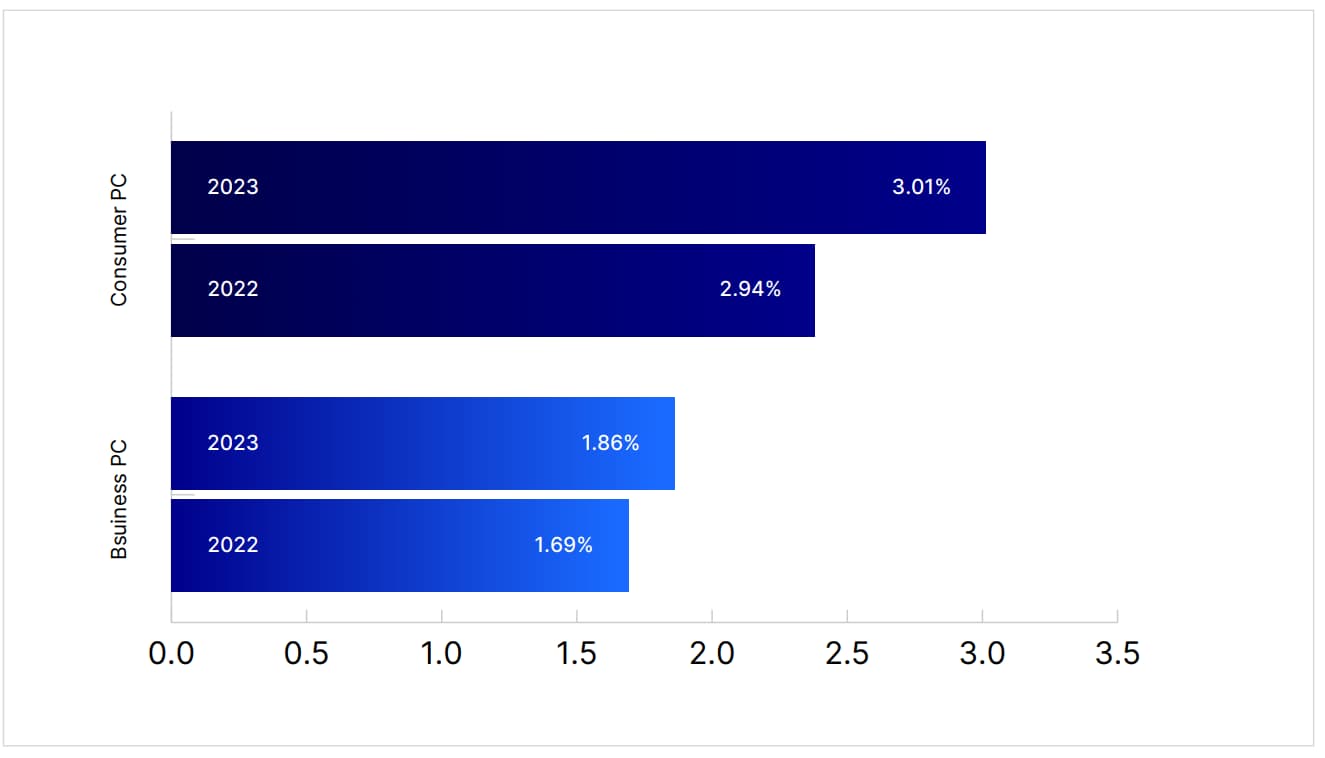
For the first time in years, malware infection rates are rising among both businesses and consumers. The uptick is primarily attributed to attackers leveraging advanced tools like generative artificial intelligence (AI), which helps them craft malware that’s more sophisticated and adaptive. Malware variants are becoming more difficult to detect, and infection methods are increasingly creative, such as using enticing email attachments or redirecting users to malicious sites via QR codes.
This new wave of malware infections serves as a stark reminder for businesses and individuals to strengthen their cyber defenses. Keep all devices updated with the latest security patches, and use reputable antivirus solutions that can block suspicious downloads and identify malicious software. Additionally, be wary of unexpected attachments or links and avoid clicking on anything that looks suspicious.
Phishing gets personal
Phishing attacks are becoming more sophisticated, thanks to tools like generative AI, which enable attackers to personalize their campaigns for maximum impact. What was once a clear distinction between mass phishing emails and more targeted spear-phishing attempts is now blurring, making it harder to distinguish between the two. Attackers can craft convincing emails that mimic legitimate brands, logos, and domains to trick unsuspecting victims into providing sensitive information or clicking malicious links.
For both businesses and consumers, this trend emphasizes the need for increased vigilance and cybersecurity awareness. Educate yourself on common phishing tactics and train employees to recognize fraudulent emails. Multi-factor authentication (MFA) can add a vital layer of protection, and carefully inspect email addresses and links before taking any action.
The critical role of cyber resilience
The report underscores the importance of adopting a multi-layered defense strategy to mitigate the impact of these evolving threats. Cyber resilience involves proactive measures to prevent attacks while also ensuring you can quickly recover if a breach occurs. For businesses, this means implementing strong antivirus software, endpoint protection solutions, and regular software updates. For consumers, being alert to suspicious emails, using secure passwords, and frequently backing up data is crucial.
A multi-layered approach integrates different layers of defense, making it much harder for an attacker to compromise all systems simultaneously. Combine antivirus tools with DNS protection, endpoint monitoring, and user training for comprehensive protection.
Regional disparities in cyber threats
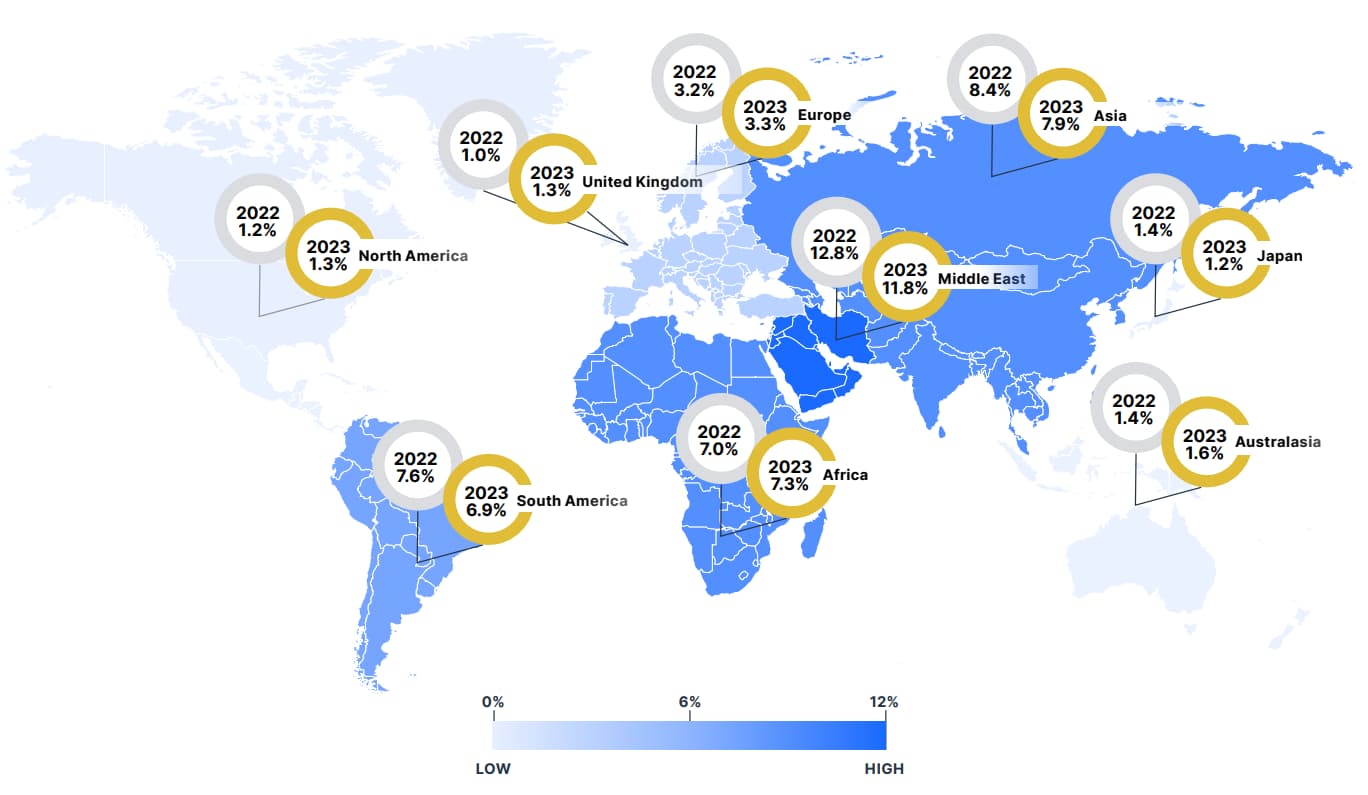
Geographical factors significantly influence the prevalence and nature of cyber threats. The report identifies regions like Asia, Africa, and South America facing higher infection rates than North America and Europe, partly due to differing economic conditions, cybersecurity maturity, and regulatory environments. Malware campaigns are often tailored to exploit regional nuances, such as the availability of local payment methods or common software vulnerabilities.
Businesses operating globally should adapt their cybersecurity strategies to account for these disparities, ensuring protections are tailored to local risks. Similarly, consumers should stay updated on the regional trends to better prepare for prevalent scams and threats in their area.
Industry-specific risks
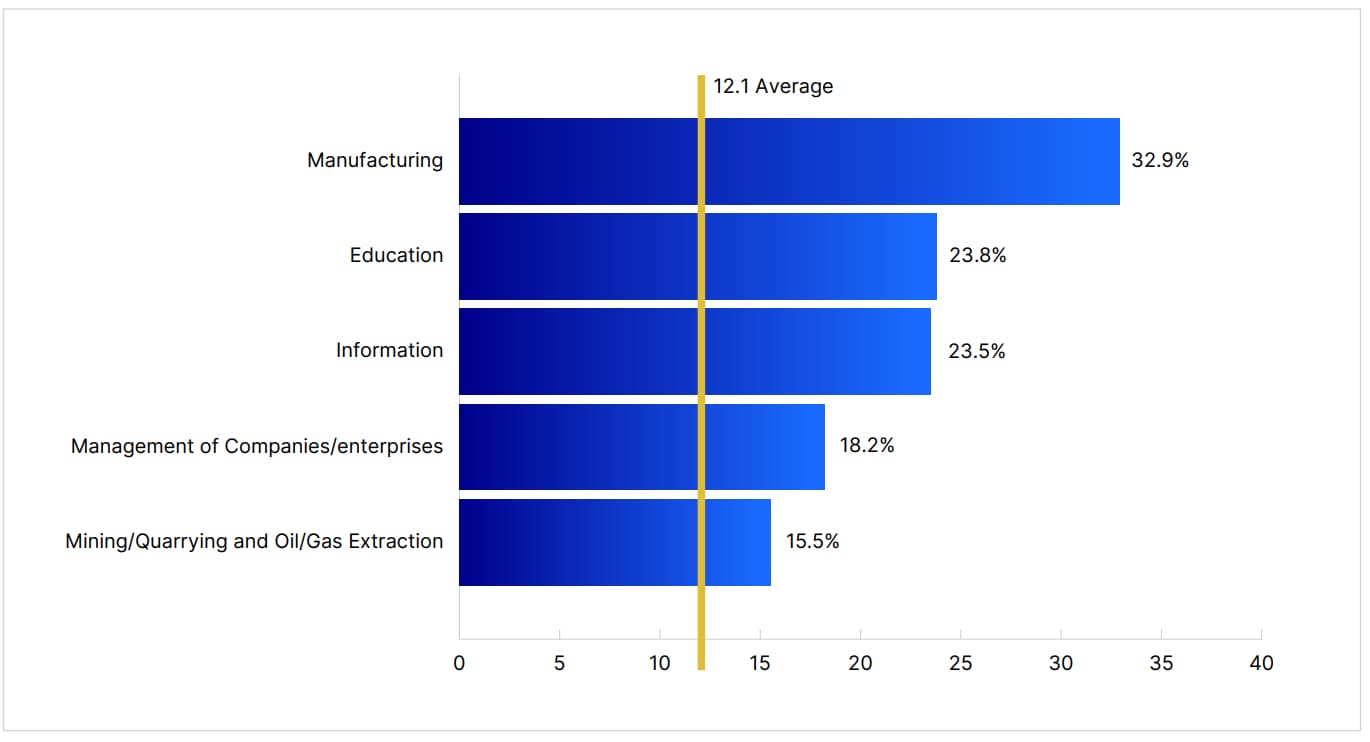
Specific industries like manufacturing, education, and healthcare are frequently targeted due to the valuable data they hold and the potential disruption caused by successful attacks. Manufacturing is particularly vulnerable to ransomware due to the high cost of production stoppages, which can prompt quicker ransom payments. Educational institutions, on the other hand, often have limited cybersecurity budgets, leaving them vulnerable to malware and phishing attacks that can compromise student and faculty data.
While businesses in these industries must enhance their cyber defenses and train staff accordingly, consumers should also be aware of how these attacks could indirectly impact them. For instance, a ransomware attack on a healthcare provider could lead to data breaches exposing patient information.
Recommendations for enhancing cybersecurity
The 2024 OpenText Threat Perspective serves as a crucial resource, offering insights that are essential for both businesses and consumers aiming to navigate the complexities of today’s cyber threat landscape. By understanding these threats and implementing a multi-layered defense strategy, we can significantly enhance our collective cyber resilience.

3 healthcare organizations that are building cyber resilience
From 2018 to 2023, healthcare data breaches have increased by 93 percent. And ransomware attacks have grown by 278 percent over the same period. Healthcare organizations can’t afford to let preventable breaches slip by. Globally, the average cost of a healthcare data breach has reached $10.93 million.
The situation for healthcare organizations may seem bleak. But there is hope. Focus on layering your security posture to focus on threat prevention, protection, and recovery.
Check out three healthcare organizations that are strengthening their cyber resilience with layered security tools.
1. Memorial Hermann balances user experience with encryption
Email encryption keeps sensitive medical data safe and organizations compliant. Unfortunately, providers will skip it if the encryption tool is difficult to use. Memorial Hermann ran into this exact issue.
Juggling compliance requirements with productivity needs, the organization worried about the user experience for email encryption. Webroot™ Email Encryption powered by Zix™ provides the solution. Nearly 75 percent of Memorial Hermann’s encrypted emails go to customers who share Webroot. Now more than 1,750 outside organizations can access encrypted email right from their inbox, with no extra steps or passwords.
2. Allergy, Asthma and Sinus Center safeguards email
The center needed to protect electronic medical records (EMR). But its old software solution required technical oversight that was difficult to manage.
Webroot™ Email Threat Protection by OpenText™ gives the healthcare organization an easy way to keep EMR secure. OpenText’s in-house research team is continually monitoring new and emerging threats to ensure the center’s threat protection is always up to date. With high-quality protection and a low-maintenance design, the IT team can focus on other projects. When patient data is at stake, the center knows it can trust Webroot.
3. Radiology Associates avoid downtime with fast recovery
Radiologists need to read and interpret patient reports so they can quickly share them with doctors. Their patients’ health can’t afford for them to have downtime.
After an unexpected server crash corrupted its database, Radiology Associates needed a way to avoid workflow interruptions. Carbonite™ Recover by OpenText™ helps the organization get back to business quickly in the event of a data breach or natural disaster. Plus, the price of the solution and ease of use gave Radiology Associates good reasons to choose our solution.
Read the full case study here:
https://www-cdn.webroot.com/1917/4905/8627/Carbonite_Radiology_Associates_CS.pdf
Conclusion
As ransomware becomes more sophisticated and data breaches occur more frequently, healthcare organizations must stay vigilant. Strong cyber resilience should be a priority so that you can protect patient privacy and maintain trust within the healthcare industry.
And you don’t have to do it alone. We’re ready to help out as your trusted cybersecurity partner. Together, we can prevent data breaches, protect sensitive data, and help you recover when disaster strikes.
Contact us to learn more about our cybersecurity solutions.
Read more about cyber attacks in the healthcare sector:
The Catastrophic Cyberattack That Shook Healthcare to Its Core
The Change Healthcare Cyberattack: A Wake-Up Call for Healthcare Cybersecurity

5 ways to strengthen healthcare cybersecurity
Ransomware attacks are targeting healthcare organizations more frequently. The number of costly cyberattacks on US hospitals has doubled. So how do you prevent these attacks? Keep reading to learn five ways you can strengthen security at your organization. But first, let’s find out what’s at stake.
Why healthcare needs better cybersecurity
Healthcare organizations are especially vulnerable to data breaches because of how much data they hold. And when a breach happens, it creates financial burdens and affects regulatory compliance. On average, the cost of a healthcare data breach globally is $10.93 million. Noncompliance not only incurs more costs but also hurts patient trust. Once that trust is lost, it’s difficult to regain it, which can impact your business and standing within the industry.
Adopting a layered security approach will help your organization prevent these attacks. Here are five ways to strengthen your cybersecurity:
1. Use preventive security technology
Prevention, as the saying goes, prevention is better than the cure. With the right systems and the right methodology, it’s possible to detect and intercept most cyberthreats before they lead to a data breach, a loss of service, or a deterioration in patient care.
Examples of prevention-layer technologies include:
- Endpoint protection keeps out malicious files, scripts, URLs, and exploits via a cloud-based architecture.
- Email encryption makes it hard for attackers to intercept sensitive medical data—just make sure the encryption tool is easy to manage and use.
- Email threat protection and continuity safeguards electronic medical records by monitoring emerging threats.
2. Provide cybersecurity training
According to Verizon, 82 percent of all breaches involve a human element. Sometimes malicious insiders create security vulnerabilities. Other times, well-intentioned employees fall victim to attacks like phishing, legitimate-looking emails that trick employees into giving attackers their credentials or other sensitive information—like patient data. In fact, 16 percent of breaches start with phishing.
When your employees receive basic cybersecurity training, they are more likely to recognize bad actors, report suspicious activity, and avoid risky behavior. You can outsource cybersecurity training or find an automated security training solution that you manage.
3. Ensure regulatory compliance
Healthcare providers are subject to strict data privacy regulations like HIPPA and GDPR. If an avoidable data breach occurs, organizations face hefty fines from state and federal authorities. The email and endpoint protection tools described above help you stay compliant with these regulations.
But sometimes a breach is out of your control. So regulators have provided guidelines for how to respond, including investigation, notification, and recovery.
4. Build business recovery plans
Adding a recovery plan to your multilayered security approach is crucial to achieving and maintaining cyber resilient healthcare. Ideally, you’ll catch most incoming threats before they become an issue. However, the recovery layer is critical when threats do get through or disasters occur.
You might think that your cloud-based applications back up and secure your data. But SaaS vendors explicitly state that data protection and backup is the customer’s responsibility of the customer. Some SaaS applications have recovery options, but they’re limited and ineffective. A separate backup system is necessary to ensure business continuity.
Reasons for implementing a solid recovery strategy include:
- Re-establishing patient trust.
- Avoiding disruptions to patient care.
- Remaining compliant with HIPPA and GDPR requirements.
Remember, lives depend on getting your systems back up quickly. That’s why your healthcare organization needs a secure, continuously updated backup and recovery solution for local and cloud servers.
5. Monitor and improve continuously
Once you have your multilayered security approach in place, you’ll need a centralized management console to help you monitor and control all your security services. This single-pane-of-glass gives you real-time cyber intelligence and all the tools you need to protect your healthcare organization, your reputation, and your investment in digital transformation. You can also spot gaps in your approach and find ways to improve.
Conclusion
Cybersecurity can seem daunting at times. Just remember that every step you take toward cyber resilience helps you protect patient privacy and maintain your credibility within the healthcare industry.
So when you’re feeling overwhelmed or stuck, remember the five ways you can strengthen your layered cybersecurity approach:
- Use preventive technology like endpoint protection and email encryption.
- Train your employees to recognize malicious activities like phishing.
- Ensure that you’re compliant with HIPPA, GDPR, and any other regulation standards.
- Retrieve your data from breaches with backup and recovery tools.
- Monitor your data and improve your approach when necessary.
Read more about cyber attacks in the healthcare sector:
The Catastrophic Cyberattack That Shook Healthcare to Its Core
The Change Healthcare Cyberattack: A Wake-Up Call for Healthcare Cybersecurity

Protecting your digital identity: Celebrating Identity Management Day
Mark your calendars for April 9, 2024
The second Tuesday of April marks Identity Management Day — a day dedicated to raising awareness about the importance of safeguarding your digital identity. But what exactly is identity management, and why do we need a whole day for it? In a world where our lives are increasingly navigated through digital apps and online accounts, understanding and managing our online identities has become paramount.
What is identity management?
So, what is identity management? Simply put, it’s the practice of ensuring that only authorized individuals have access to your sensitive information and online accounts. This encompasses everything from protecting your passwords to being vigilant against phishing scams and online fraud. But why dedicate an entire day to this? The answer lies in the ever-evolving landscape of cybersecurity threats. Cybercriminals are constantly devising new ways to steal personal information and exploit vulnerabilities in our digital lives. Identity Management Day serves as a reminder that protecting our identities isn’t just a one-time task — it’s an ongoing commitment that requires vigilance and proactive measures all year round.
10 tips to keep your identity safe online
Here are some practical tips to help you keep your identity safe online:
- Get the latest anti-virus software
Investing in reliable anti-virus software is like putting a protective shield around your devices, such as your PCs, Macs, mobile devices, Chromebooks, and tablets. Make sure to keep it updated to guard against the latest threats. - Update your Internet browser
Browser updates often contain security patches that address known vulnerabilities. Don’t ignore those update prompts — they could be the key to keeping your identity and online activities secure. - Create strong passwords and use different ones for each account
This may seem like a hassle, but it’s one of the most effective ways to thwart cyberattacks. Use a combination of letters, numbers, and special characters, and consider using a reputable password manager to securely keep track of them. - Be careful about using public Wi-Fi
Public Wi-Fi networks — hotspots in coffee shops, malls, airports, hotels, and other places — are convenient. But they can also be a breeding ground for hackers. Make sure your connection is encrypted by looking for the padlock symbol or “https” in the address bar to the left of the website address. And avoid accessing sensitive information or making financial transactions while connected to public Wi-Fi. - Use a VPN to browse privately
A virtual private network (VPN) enhances your online privacy and helps keep your identity safe. By encrypting your internet connection and masking your IP address, a good VPN shields your online activities from prying eyes, hackers, and nosy advertisers. - Don’t let your browser remember your login details
While convenient, allowing your browser to remember passwords puts your accounts at risk if your device falls into the wrong hands. Instead, enter your credentials each time for added security. - Learn to spot fake emails and websites
Fake emails like phishing scams are a common tactic used by cybercriminals to trick unsuspecting individuals into divulging sensitive information. Be wary of unsolicited emails or unfamiliar websites, and never click on suspicious links or attachments. For SMBs, fostering a culture where your employees become your strongest security allies is essential. Offer security awareness training to help them recognize and avoid potential threats. - Avoid online fraud and con tricks
If something seems too good to be true, it probably is. Exercise caution when sharing personal or financial information online and be skeptical of offers that promise unrealistic rewards or benefits. You should also be cautious about the personal information you share on social media. Remember, fraudsters can potentially exploit your posts to compromise your identity. Read 7 Cyber Safety Tips for more guidance on how to spot these fake offers.
For small businesses, you’ll want to safeguard your own data and that of your customers. In addition to ensuring that your employees adopt to the above eight tips, here are two important tips for you to advance your company’s identity management efforts:
- Prioritize vulnerability assessments
Conduct regular vulnerability assessments to identify potential weaknesses in your company’s security infrastructure, including endpoints such as your computers, laptops, and mobile devices. By proactively addressing these vulnerabilities and implementing robust endpoint protection and policies, you can significantly reduce the risk of unauthorized access to sensitive information. - Get to know what data you have, what’s sensitive, and protect it
Understanding the types of data your business collects, stores, and processes is essential for effective identity management. Identify sensitive information such as customer payment details or personal identifiers and implement appropriate safeguards to protect it from unauthorized access or misuse. Doing so is a sound business practice and also aids in meeting regulatory standards, if applicable to your business.
By staying informed, adopting best practices, and leveraging available resources, we can all play a part in creating a safer online environment for ourselves and others.
For those looking for additional support in managing their digital identities, consider exploring reputable cybersecurity solutions such as Webroot, which offers a range of products designed to keep your information secure. You can also check out the National Cybersecurity Alliance for ways you can get involved in Identity Management Day. Remember, protecting your identity is not just a one-day affair — it’s a continuous effort that requires diligence and awareness.

Understanding brute force attacks: The persistent threat in cybersecurity
Brute force attacks illustrate how persistence can pay off. Unfortunately, in this context, it’s for bad actors. Let’s dive into the mechanics of brute force attacks, unraveling their methodology, and focusing on their application. Whether it’s Remote Desktop Protocol (RDP), or direct finance theft, brute force attacks are a prime tactic in the current cybersecurity landscape.
What is a brute force attack?
A brute force attack is a cyber attack where the attacker attempts to gain unauthorized access to a system or data by systematically trying every possible combination of passwords or keys. This method relies on the sheer power of repetition and the computational capacity to try thousands, if not millions, of combinations in a short time span. Think of it as trying every key on a keyring until finding the one that unlocks a door.
Types of brute force attacks
- Simple brute force attacks: This basic approach involves trying all possible combinations of characters until the correct one is found.
- Dictionary attacks: A more refined method that uses a list of pre-existing passwords, phrases, or commonly used combinations instead of random permutations. There are many already leaked password lists that are commonly used, and they grow after every breach.
- Hybrid attacks: Combining elements of both the simple and dictionary approaches, often tweaking common passwords slightly to guess more complex passwords.
The role of GPUs in brute force attacks
Graphic Processing Units (GPUs) have revolutionized not just gaming and graphic design, but also the world of cybersecurity. Their powerful parallel processing capabilities make them particularly adept at handling the computational demands of brute force attacks. Unlike Central Processing Units (CPUs) that process tasks sequentially, GPUs can perform thousands of operations simultaneously, drastically reducing the time required to crack passwords or encryption keys.
Accelerating brute borce techniques
Cybercriminals exploit GPUs to accelerate the brute force process, enabling them to try billions of password combinations in seconds. This brute force capability poses a significant threat to systems protected by weak or commonly used passwords. It underscores the necessity for robust password policies and advanced security measures like Multi-Factor Authentication (MFA) and encryption methods resilient against GPU-powered attacks.
Financial applications of brute force attacks
The financial implications of brute force attacks can be profound, ranging from direct financial theft to substantial reputational damage leading to loss of business.
Direct Financial Theft
In some cases, attackers aim to gain unauthorized access to financial systems or payment platforms. By cracking login credentials through brute force, they can transfer funds, manipulate transactions, or steal sensitive financial information, leading to direct monetary losses.
The role of RDP in brute force attacks
Remote Desktop Protocol (RDP) is a proprietary protocol developed by Microsoft that allows a user to connect to another computer over a network connection with a graphical interface. While RDP is a powerful tool for remote administration and support, it has also become a favored vector for brute force attacks for several reasons:
- Widespread use: RDP is commonly used in businesses to enable remote work and system administration.
- Open ports: RDP typically requires port 3389 to be open, making it a visible entry point for attackers scanning for vulnerabilities.
- Direct access: Successfully breaching an RDP session can give attackers direct control over a victim’s computer, allowing for the deployment of malware, ransomware, or theft of sensitive information.
Real-world examples of brute force attacks via RDP
- Ransomware deployment: One of the most nefarious uses of brute force attacks on RDP is for the deployment of ransomware. Once access is gained, attackers can encrypt the victim’s files, demanding a ransom for their release. The WannaCry and Ryuk ransomware attacks are notable examples where such tactics were likely utilized.
- Credential stuffing: In some cases, attackers use brute force tactics to validate stolen username and password combinations against accessible RDP servers. This method relies on the assumption that many users reuse their credentials across different services.
- Network infiltration: Upon gaining access via RDP, cybercriminals can use the compromised system as a foothold to explore and exploit further vulnerabilities within a network, aiming for more valuable data or systems.
Mitigating the Risk
Protecting against brute force attacks, especially on RDP, involves a multi-faceted approach:
- Strong password policies: Enforce complex, unique passwords and consider the use of multi-factor authentication (MFA) to add an extra layer of security.
- Account lockout policies: Implement policies that lock user accounts after a certain number of failed login attempts to hinder brute force efforts.
- Network level authentication (NLA): NLA requires users to authenticate before establishing an RDP session, significantly reducing the risk of brute force attacks.
- VPN usage: Restrict RDP access to users connected through a Virtual Private Network (VPN), reducing the exposure of RDP to the open internet.
- Monitoring and alerts: Use security tools to monitor for repeated failed login attempts and configure alerts to notify administrators of potential brute force activities.

The Marvels and Challenges of AI
Let’s delve into the fascinating world of Artificial intelligence (AI), unpacking its concepts, implications, and real-world applications. Brace yourself for an extended journey through the marvels and challenges of artificial intelligence.
Part 1: Unleashing marvels in our digital lives
Generative AI and chatbots
AI has transcended its sci-fi origins to become an integral part of our daily existence. Let’s explore both the light and the dark sides of this transformative force.
1. Generative AI: fueling creativity
Generative AI is a subset of AI, empowering machines to create human-like content. These models learn patterns from vast amounts of data and then generate new, original content.
Here are just some of the ways they’re shaping our world.
A. Text generation
Generative models like OpenAI’s GPT-3 have garnered attention with their creative prowess. Imagine a poet AI composing thought-provoking verses or an author AI writing entire novels. These algorithms analyze existing text and generate coherent, context-aware responses. From automated customer service chats to personalized email drafts, generative text models enhance efficiency and convenience.
Example:
Chatbot: “Dear John, I hope this email finds you well. I wanted to discuss the upcoming project deadline. Could we possibly extend it by a week? Your prompt response would be greatly appreciated.”
B. Art and music creation
Beyond text, generative AI ventures into the realms of art and music. AI artists create digital works, mimicking famous styles or inventing entirely new ones. Music composition algorithms generate enchanting melodies, experimenting with genres and instruments. The fusion of human creativity and machine learning opens up uncharted creative territories.
Examples:
Art AI: “Behold ‘digital Impressionism’—a canvas painted by an algorithm. Inspired by Monet, it captures the play of light on water, blending pixels into ethereal strokes.”
Sora: An AI model that can create realistic and imaginative scenes from text instructions, Sora allows users to create short videos based on simple text prompts.
2. Chatbots: Your digital companions
Chatbots, such as the renowned ChatGPT, engage in natural conversations with users. They’re not mere rule-based question-answer systems; they understand context, learn from interactions, and adapt their responses.
Here’s how chatbots are transforming our lives:
A. Virtual assistants
Chatbots act as tireless virtual assistants, handling tasks like setting reminders, booking appointments, and providing weather updates. They’re available 24/7, ensuring productivity and convenience.
Example:
User: “Hey chatbot, remind me to buy groceries tomorrow.” Chatbot: “Certainly! I’ll set a reminder for tomorrow at 10:00 am.”
B. Customer support
In the business world, chatbots assist customers round the clock. They resolve queries, guide users through troubleshooting steps, and even process transactions. Their efficiency reduces wait times and improves customer satisfaction.
Example:
Customer: “My order hasn’t arrived yet. Can you check its status?” Chatbot: “I apologize for the delay. Let me track your order. It should arrive by Friday.”
C. Virtual partners / AI romance
AI has developed beyond the simple “swipe right/left” paradigm of modern dating apps and now even eclipsed the human-machine relationship depicted in the Spike Jonze movie, Her (2013). Loosely based on and extrapolated from chatbots such as Apple’s Siri or Google’s Alexa, Scarlett Johannsen’s character interacts with the man played by Joaquim Phoenix in ways that were not truly possible at the time.
Example:
Today, apps like Candy.ai promise users “realistic yet fantasy-fueled relationships” using advanced artificial intelligence technology to create the ideal AI girl/boyfriend according to the user’s preferences.
D. Content creation
Chatbots can compose emails, articles, and reports. Imagine a chatbot helping you draft that important client email or summarizing a lengthy document. As they learn from user interactions, their writing style adapts, making them valuable co-authors.
Example:
Chatbot: “Here’s a concise summary of the quarterly report. Key takeaways: revenue growth, cost optimization, and increased customer engagement.”
Medical breakthroughs and personalization
1. AI in healthcare
A. Diagnosis and prediction
AI analyzes medical data, aiding in disease diagnosis and predicting patient outcomes. Imagine an AI-powered system detecting early signs of cancer or suggesting personalized treatment plans based on genetic profiles. Precision medicine becomes a reality, optimizing recovery and minimizing side effects.
Example:
AI system: “Based on your genomic markers, we recommend a tailored treatment plan for your rheumatoid arthritis, including targeted therapies and lifestyle adjustments.”
B. Drug discovery
AI accelerates drug discovery by sifting through vast chemical databases. It identifies potential candidates, predicts their efficacy, and expedites research. These breakthroughs hold the promise of saving lives and improving global health.
Example:
Researcher: “Our AI model identified a novel compound with anti-viral properties. Let’s test it in vitro.”
4. Personalization algorithms
AI algorithms can personalize our experiences across platforms in several ways, here are two we encounter in our daily lives:
A. Lifestyle recommendations
From Netflix to social media, AI analyzes our preferences and behavior. It recommends movies, articles, and products tailored to our tastes. Imagine a world where your news feed aligns perfectly with your interests, introducing you to relevant content. But this is only the tip of the iceberg.
When AI is combined with big data and personal data (gleaned from biometric sensors in wearable devices—the step counter in the Apple Watch or iPhone being one of the simplest examples) it can recommend diet and health options, tailor optimal workouts, create psychological profiles, even help users explore career choices, assist with dating and partner match recommendations, and so much more.
Example:
Smart watch: “Based on your height, weight, BMI, and fitness level, here is a diet and exercise regime designed to help you achieve your fitness goals.”
B. Targeted advertising
E-commerce platforms use AI to display ads relevant to individual users. These algorithms consider browsing history, demographics, and purchase behavior. While sometimes controversial, personalized ads can enhance user engagement and drive sales—especially when they get their timing and targeting right!
Example:
Online retailer: “Looking for running shoes? Check out our latest collection!”
Transforming industries
1. Finance, manufacturing, and logistics
A. Process automation
AI streamlines repetitive tasks, reducing human error. In finance, algorithms handle stock trading, fraud detection, and credit risk assessment. In manufacturing, robots assemble products with precision. Logistics companies optimize routes and delivery schedules, minimizing costs.
Example:
Algorithm: “Sell 100 shares of XYZ stock if it drops below $50. Execute.”
B. Data-driven decisions
AI analyzes vast data sets, providing insights for strategic decisions. Manufacturers optimize supply chains, predicting demand fluctuations. Financial institutions assess investment risks, adapting to market dynamics. Data-driven decision-making becomes the norm.
Example:
Supply chain manager: “Our AI model recommends adjusting inventory levels based on seasonal trends. Let’s implement it.”
2. Smart cities
A. Traffic management
AI monitors traffic flow, adjusts signal timings, and predicts congestion. Smart cities optimize transportation networks, reducing commute times and environmental impact.
Soon, self-driving cars equipped with advanced AI will communicate with each other to optimize traffic flow, adjusting speeds, merging seamlessly, and avoiding bottlenecks. In this future network, vehicles cooperatively navigate intersections without the need for traffic lights or stop signs.
Road accidents caused by human error are set to become a thing of the past. Self-driving cars, relying on sensors, cameras, and AI algorithms, react faster and more accurately than humans. Unlike humans, algorithms don’t get distracted, fatigued, or impaired which drastically reduces accidents.
In this AI EV future, our roads will transform into safer, more efficient spaces, where traffic snarls and collisions are relegated to history.
Example:
Traffic control center: “Route traffic away from downtown during rush hour. Optimize traffic light cycles for smoother flow.”
B. Energy efficiency
Smart grids balance energy supply and demand, minimizing wastage. AI algorithms predict peak usage hours, ensuring efficient distribution. Renewable energy sources integrate seamlessly into the grid.
Example:
Smart meter: “Solar panels are generating excess energy. Divert it to the grid or store it in batteries?”
C. Waste management
AI helps optimize waste collection routes, reducing landfill overflow. Sensors can be used to detect fill levels, alerting sanitation crews when bins need emptying. These and other innovations are helping us build cleaner, more sustainable cities.
Example:
Garbage truck dispatcher: “Route adjustment: prioritize areas with overflowing bins.”
Part 2: AI and the need for vigilance in our digital lives
The rise of AI scams
1. Deepfakes: Deception in high definition
The rapid ascent of generative AI has sparked both fascination and apprehension. Deepfakes, a byproduct of this technology, represent the downside of its dual nature. These hyper-realistic manipulations allow cybercriminals to impersonate trustworthy figures, including celebrities, politicians, and even family members. Here’s how deepfakes impact our digital landscape:
A. Impersonation of trustworthy figures:
Cybercriminals exploit deepfakes to create eerily accurate impersonations. Imagine receiving a phone call from a seemingly genuine bank manager, requesting sensitive account details for “security verification.” What the victim doesn’t know is they’re interacting with an AI-generated persona. Financial losses and reputational damage follow. Victims trust these deceptive voices, unaware of the illusion.
Example:
Deepfake Voice: “Hello, this is your bank manager. We need your account details for security verification.”
Or : “Hey Granny, could you please transfer me some money? I need to buy a new computer for school?”
B. Luring victims into fraudulent schemes:
Scammers craft persuasive narratives using deepfakes. These narratives promise quick riches, job opportunities, or romantic connections. Victims, enticed by the illusion, fall prey to these schemes.
The line between reality and deception blurs, leaving individuals vulnerable to financial exploitation.
Example:
Scammer: “Invest in this AI-powered cryptocurrency—watch this celebrity testimonial!”
Deepfakes challenge our ability to discern truth from fiction, emphasizing the need for vigilance and awareness in an AI-driven world.
Example 2:
In February 2024, an unsuspecting finance worker, attending an online meeting, interacted with entirely AI-fabricated colleagues who convinced him to confirm a false transaction resulting in a staggering $25 million loss for the company.
Algorithmic bias and privacy violations
1. Discrimination amplified
AI algorithms inherit biases from their training data. Unfortunately, facial recognition systems often misidentify people of color due to skewed data sets. These errors perpetuate societal prejudices, leading to real-world consequences.
Imagine being denied access or services because an AI system fails to verify your identity correctly.
Example:
Facial recognition system: “Sorry, we cannot verify your identity. Please try again.”
2. The erosion of privacy
AI’s insatiable appetite for personal information raises ethical concerns. Algorithms analyze sensitive data without explicit consent, eroding privacy boundaries.
Our digital identities hang in the balance as AI-driven ad targeting systems comb through browsing histories, serving personalized ads. Imagine receiving tailored advertisements based on your most intimate online activities.
Example:
AI ad targeting: “Based on your browsing history, here are personalized ads just for you!”
As we navigate the AI landscape, addressing bias and safeguarding privacy become critical imperatives.
The strange life of chatbots
1. Emotional connections with machines
As we forge connections with AI, we grapple with the paradox of intimacy and artifice. Chatbots straddle the line between utility and emotional impact. Users can form genuine bonds with these AI companions, despite their artificial nature.
While AI dating sites and chatbots as virtual companions offer convenience and novelty, there are significant downsides to consider. In our quest for digital companionship, we risk losing genuine human connections. AI chatbots lack empathy, intuition, and the emotional depth that only real-life interactions provide.
Virtual boyfriends and girlfriends shield us from the complexities of real-world relationships, which can involve disagreements, struggle, and the need for compromise. By opting for AI companions, we miss out on the growth that comes from navigating challenges together.
Another AI chatbot drawback is a tendency to reinforce traditional gender roles. Female-voiced assistants often play subservient roles, perpetuating stereotypes, and reinforcing negative perceptions of gender dynamics in real life. Additionally, there have been cases of AI chatbots behaving inappropriately, including sexual harassment.
2. Disinformation and national security
Deepfakes, a menacing offspring of AI, pose significant threats to society. These hyper-realistic manipulations undermine election outcomes, social stability, and national security.
By manipulating public opinion or spreading fabricated news, deepfakes create distrust and confusion. Educating the public about their existence and potential impact is crucial.
Example:
Disinformation campaign: “Watch this video showing how Candidate X was caught in a scandal—spread the word!”
Human psychology and confirmation bias—the tendency to seek out and prefer information that supports our preexisting beliefs—which is already amplified by social media, becomes even more dangerous when powered by AI and fake content.
This process of actively looking for evidence that aligns with what we already think or know, while ignoring or dismissing information that contradicts our beliefs, is arguably helping to fuel some of the divisions we are seeing in democratic society today.
Balancing marvels and vigilance
Moving forward, it is essential that we understand the nuances of AI. Its marvels are reshaping our world, but vigilance is crucial. As we embrace the innovations, we must also safeguard against the dark shadows of deepfakes and misinformation. We must navigate this evolving landscape with curiosity, responsibility, and a commitment to ethical AI.
What can I do at my level?
Embrace technology’s benefits but be aware of the pitfalls. Here’s how to protect yourself and your loved ones:
Exercise Judgment and Due Diligence:
- Question what you encounter online.
- Verify information before sharing or acting upon it.
Fortify Your Digital Armor:
- Use security software, VPNs, strong passwords, and two-factor authentication.
- Regularly update your software.
Mind Your Digital Footprints:
- Be mindful of what you share online.
- Adjust privacy settings and periodically review your digital footprint.
Remember, common sense is your secret weapon against misinformation and AI-driven threats.

7 cyber safety tips to outsmart scammers
Welcome to the wild west of the digital world where cyber scammers lurk around every pixelated corner. Cybercrime isn’t just a futuristic Hollywood plotline, it’s a real threat that targets everyone—from wide-eyed kids to seasoned adults and wise grandparents.
And guess what? It’s on the rise faster than your Wi-Fi connection during peak hours (okay, maybe not that fast, but you get the gist). So, hoist the sails as we cruise through the seven seas of cyber safety.
Identifying scams
Before we dive headfirst into the cyber safety tips, let’s equip ourselves with the ultimate weapon: knowledge. Scams are the digital equivalent of a snake oil salesperson peddling miracle cures. They come in all shapes and sizes, lurking in the shadowy corners of the internet.
Let’s embrace the golden rule of scam detection: skepticism.
Whether it’s a promise of untold riches, a once-in-a-lifetime opportunity, or a free Caribbean cruise courtesy of a Nigerian prince, approach with caution and a healthy dose of skepticism.
Now, let’s take a quick tour through the terrain of common cyber scams:
- Phishing scams
Ah, phishing scams, the bane of our digital existence. These sneaky scams involve fake emails posing as messages from familiar faces or reputable companies. They’ll try to sweet-talk you into clicking on suspicious links or divulging sensitive information like passwords or credit card details. Remember: real companies don’t ask for your personal data via email. - Sweepstakes and awards scams
Congratulations! You’ve just won a brand new car, a tropical vacation, and a lifetime supply of unicorn-shaped cookies—all you need to do is pay a small processing fee. Sound too good to be true? That’s because it is! These scams offer you instant wealth but are really just clever ruses to empty your wallet faster than you can say “jackpot.” - Investment scams
Picture this: a golden opportunity to double your money with zero risk. Investment scams lure unsuspecting victims with the promise of sky-high profits. Don’t let these offers cloud your judgment. Always do your due diligence before investing your hard-earned cash. - Lawsuit or tax scams
Lawsuit and tax scams thrive on instilling fear and panic, claiming you owe urgent payments. When in doubt, verify the legitimacy of any claims before reaching for your wallet. - Romance scams
Romance scams prey on the trusting hearts of hopeful romantics, weaving elaborate tales of love and devotion before swooping in for the financial kill. Remember: anyone who asks for money online is more likely to break your heart than mend it. - Tech support scams
These imposters offer remote assistance to fix nonexistent problems with your laptop or devices while gaining access to your sensitive data. Remember: legitimate tech support doesn’t come knocking unsolicited. If in doubt, just delete the email and seek help from trusted sources.
Equipped with this knowledge, you’re ready to navigate the digital minefield with confidence. You can also be a good internet citizen by forwarding these scams to the U.S. government’s Cybersecurity & Infrastructure Security Agency (CISA) at phishing-report@us-cert.gov.
Your 7 tips to stay safe online
- Use strong passwords
Let’s kick things off with the basics. Your password is the digital key to your castle, so make sure it’s not something as flimsy as ‘123456’ or ‘password.’ Get creative! Mix uppercase, lowercase, numbers, and special characters like a mad scientist concocting a secret potion. And don’t reuse passwords across multiple accounts unless you want to throw a welcome party for cybercriminals. - Keep your devices updated
Newsflash: Cybercriminals love exploiting vulnerabilities in outdated software like it’s Black Friday at the cybercrime emporium. Stay one step ahead by keeping your devices and applications updated. Those pesky software updates aren’t just about adding a new emoji, they often contain vital updates to fix security issues. - Lockdown your privacy settings
Your online profiles are like open books to cyber snoops unless you lock them down. Take a few minutes to review and adjust your privacy settings on platforms like Facebook, Instagram, and YouTube. Limit who can see your posts, tag you in photos, or slide into your DMs without an invitation. - Safeguard your privacy with a trustworthy VPN
In the digital-verse, protecting your online privacy is paramount, like guarding the secret recipe to your grandma’s famous carrot cake. That’s where a virtual private network (VPN) swoops in like a digital superhero to save the day. By encrypting your internet connection and masking your IP address, a good VPN shields your online activities from prying eyes, hackers, and nosy advertisers. - Use two-factor authentication
Two-factor authentication (2FA) adds an extra layer of security for your account logins by having you not only enter your password but also provide a second form of verification, such as a one-time code texted to your phone. It’s like having two bouncers screening out any shady characters trying to hack into your accounts. - Backup your data
Picture this nightmare scenario: Your laptop is suddenly hijacked by a malware infection or a ransomware attack encrypting all your files and holding them hostage. But fear not! By regularly backing up your data to the cloud or an external hard drive, you can rest easy knowing that your digital treasures are safe and sound. - Safeguard your loved ones
Internet scams can be devastatingly effective when targeting vulnerable groups such as the elderly, children, or those less tech savvy. So it’s crucial to designate someone as the cybersecurity leader within your family. One of your top priorities should be to ensure that everyone’s devices are equipped with robust identity protection and antivirus software. Think of it as fortifying your digital fortress, shielding your loved ones from the threats lurking in the internet world.
Congratulations, you’ve just leveled up your digital defense game! By implementing these seven cyber safety tips, you can protect yourself and your loved ones from cyber scammers. Stay safe out there!
| Need help deciding which Webroot product is right for you? Take our short quiz to discover the ideal plan for safeguarding your devices, privacy, and identity—whether it’s for you or your entire family. |